Czy te problemy brzmią znajomo?
- Praca z dużą liczbą dokumentów papierowych lub skanów, z których dane trzeba wprowadzić do systemu komputerowego to codzienność twojej firmy?
- Ręczne przepisywanie danych jest żmudne, męczące i łatwo o błędy?
- Etatowi pracownicy poświęcają zbyt dużo czasu na wprowadzanie danych – ich praca jest mało efektywna?
- Monotonność zadań skutkuje dużą rotacją pracowników zatrudnionych do wprowadzania danych, a więc wysokie koszty rekrutacji i niską wydajność pracy nowo zatrudnionych osób?
Poznaj iDoka
iDoc to rozwiązanie wykorzystujące algorytmy AI/ML do:
- automatycznego czytania i kategoryzowania skanów dokumentów
- oraz uzupełniania baz danych systemów firmowych odpowiednimi informacjami.
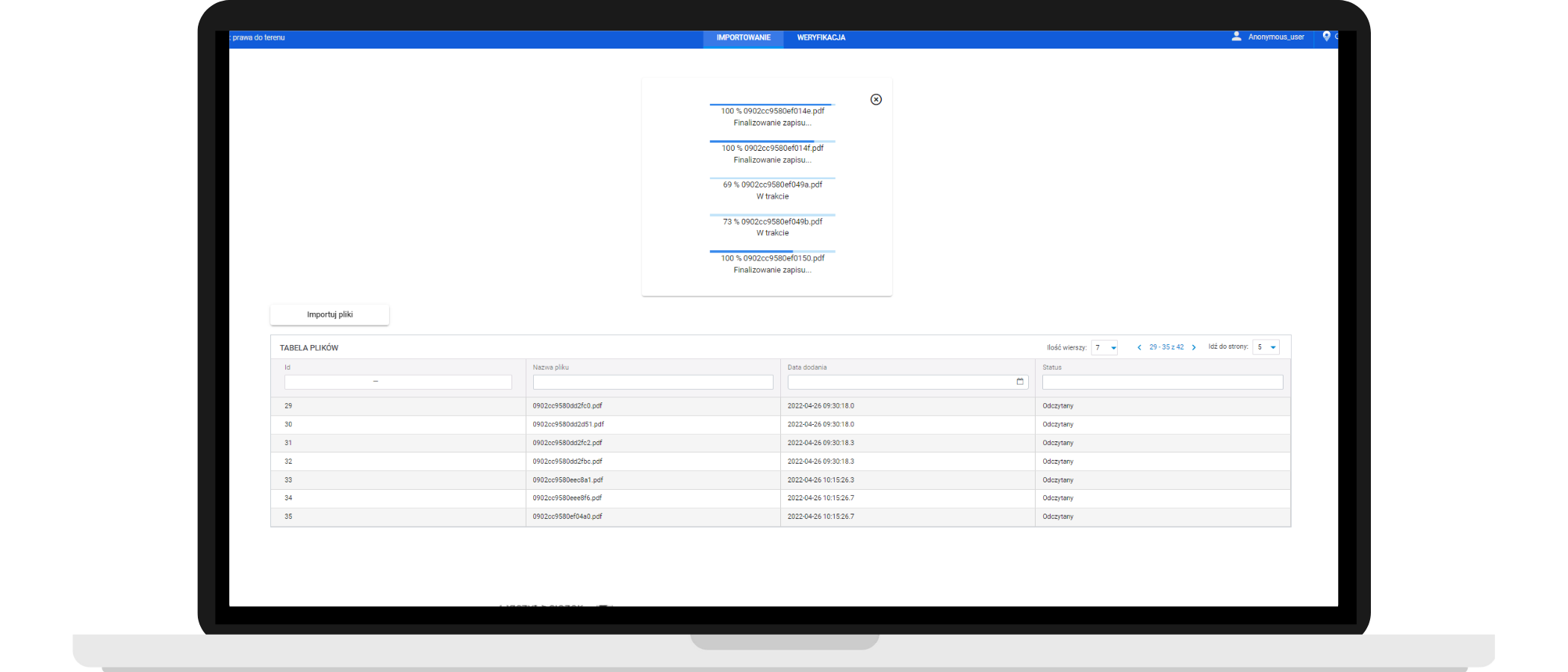
Jak działa iDoc?
Weryfikacja odczytanych danych (człowiek + AI)
Wysłanie danych do innych systemów
iDoc zastępuje ręczne przepisywanie danych z dokumentów do bazy
Algorytm czyta informacje w dokumencie i na tej podstawie rozpoznaje jaki to dokument (kategoryzuje go). Następnie, zbiera dane z dokumentu i zapisuje je we własnej bazie danych. Ta baza danych może być następnie zintegrowana z bazami danych lub systemami firmy.

iDoc jest dostępny on premise lub w chmurze

Baza danych iDoc może służyć jako uzupełnienie już istniejącej bazy danych firmy lub działać jako niezależna baza danych.
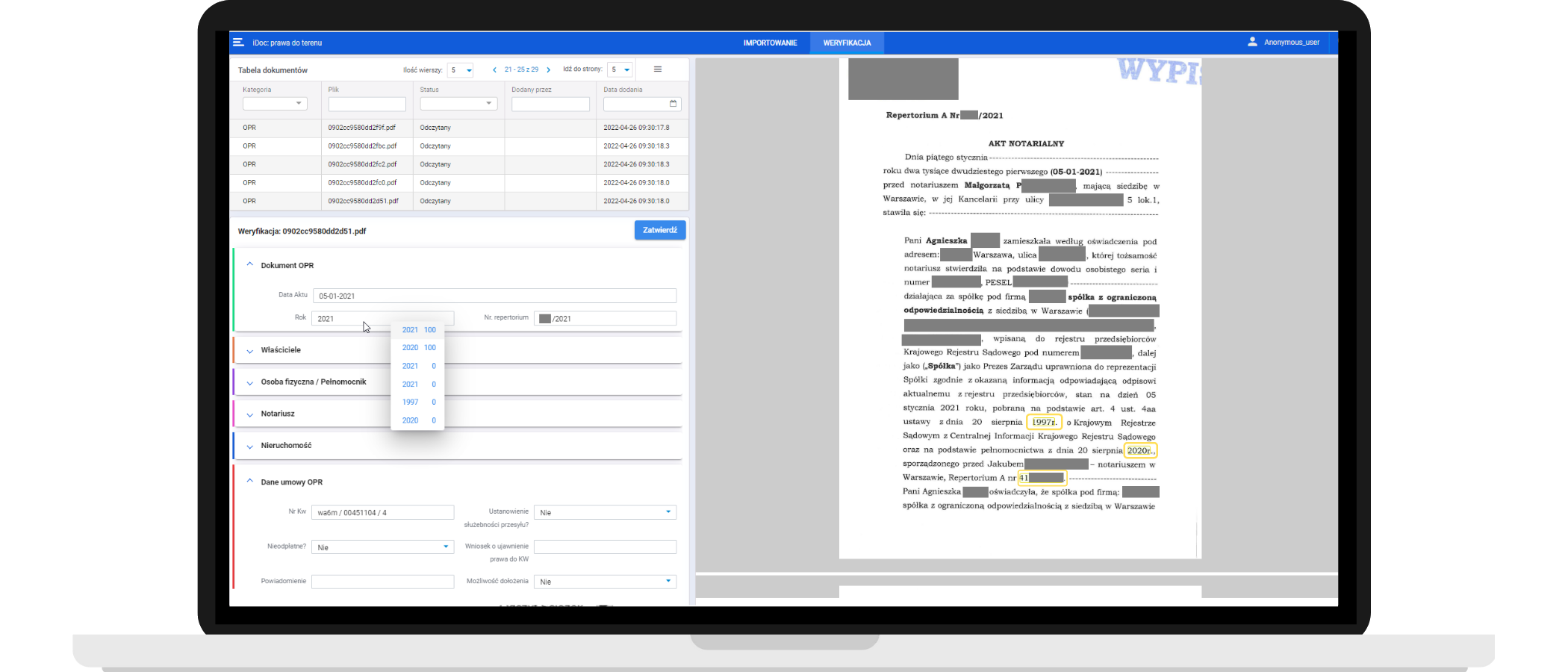
Ręczne a automatyczne wprowadzanie danych
W ciągu dnia pracy

Człowiek jest w stanie skategoryzować (rozpoznać, z jakim dokumentem ma do czynienia) około 3100 stron.

Algorytm sztucznej inteligencji skategoryzuje w tym samym czasie powyżej 30000 stron przy dokładności minimum 96%.*

Człowiek odczyta i wprowadzi do bazy danych około 2000 atrybutów.

Algorytm sztucznej inteligencji opracuje około 20 000 atrybutów przy dokładności około 85%* (czyli 10 razy więcej).
*100% dokładność zapewni osoba weryfikująca automatycznie przetworzone dane
Jakie informacje potrafi odczytać iDoc?
iDoc odczytuje z dokumentów wszystkie typy informacji, które zostały wcześniej zdefiniowane dla określonej kategorii dokumentu. Są to między innymi:
Dane adresowe (adresy pocztowe, numery działek, obrębów)
Daty i okresy obowiązywania
Inne daty wymienione w dokumencie
Szczegóły obiektów wymienionych w dokumencie
(nazwa obiektu, ilość, jego typ, powierzchnie, długości)
Dane o stronach umowy
(nazwy firm, właściciele, pełnomocnicy, notariusz, numery PESEL)
Numery identyfikujące umowy i inne (nr dok. inwestycyjnej, nr repertorium, nr księgi wieczystej, nr zlecenia)
Informacje o przedmiocie zawartej umowy (stan prawny, rodzaj umowy, powiadomienie o wygaśnięciu umowy)
Informacje o płatnościach (brutto, netto, cykliczność)
Pozostałe szczegółowe dane
Zakres odczytywanych informacji można rozszerzać o kolejne kategorie dokumentów i kolejne typy danych – zgodnie z indywidualnymi wymaganiami Twojej branży czy przedsiębiorstwa.
Jak dbamy o bezpieczeństwo Twoich danych?
W naszych rozwiązaniach kładziemy szczególny nacisk na bezpieczeństwo rozwiązań i ochronę danych naszych klientów. Stosujemy zalecenia i dobre praktyki w zakresie bezpieczeństwa, wynikające m.in. z norm ISO 27001 i NIST.
W procesie wytwarzania oprogramowanie rozwiązania są testowane zgodnie z metodykami OWASP TOP10 i OWASP ASVS. Stosujemy statyczną analizę kodu, weryfikację podatności obrazów i komponentów firm trzecich.
Przestrzegamy ścisłego podziału pomiędzy developmentem a środowiskami produkcyjnymi, do których dostęp mają wyłącznie administratorzy rozwiązania.
Dostęp administracyjny jest chroniony dwustopniową weryfikacją, z metodami uwierzytelnienia odpornymi na phishing.
Stosujemy pełną separację danych poszczególnych klientów, co uniemożliwia przypadkowy dostęp niepowołanych osób z innej organizacji.
Zajrzyj na nasz blog i dowiedz się więcej o iDoku!
Chcesz dowiedzieć się więcej na temat pozyskiwania informacji z dokumentów dzięki sztucznej inteligencji? Przeczytaj nasze artykuły oraz Case Study!
Sprawne pozyskanie informacji o służebności z dokumentów z pomocą AI
Zobacz, jak dzięki wykorzystaniu AI do odczytywania danych, Stoen Operator skrócił czas przeznaczony na archiwizację umów o służebności i aktów notarialnych o ponad 60%.
Dla kogo przeznaczony jest iDoc?
Rozwiązanie iDoc jest dla Ciebie, jeśli:
iDoc sprawdzi się wszędzie tam, gdzie powstają duże ilości dokumentów papierowych, zawierające dane, które muszą być wprowadzone do systemów komputerowych, aby mogły być dalej przetwarzane i wykorzystywane w codziennej pracy.
Przykładami takich miejsc są:
Firmy ubezpieczeniowe
Banki
Urzędy miasta
Wydziały nieruchomości, geodezji czy księgowe firm z sektora:
Energetyki
Ciepłownictwa
Gazownictwa
Wodno-kanalizacyjnego
Telekomunikacji
Budownictwa
Reklamy i komunikacji
Nieruchomości
Rozwiązanie dopasowywane do indywidualnych potrzeb
iDoc bazuje na algorytmach uczenia maszynowego i sztucznej inteligencji (AI/ML). Algorytmy można douczać w zależności od potrzeb, dlatego rozwiązanie można dostosować do odczytywania różnego rodzaju dokumentów – właściwych dla branży czy nawet konkretnej firmy.
Przykładowe obszary zastosowania
Dokumentacja dotycząca praw do terenu
- akty notarialne,
- umowy dzierżawy, najmu
- umowy udostępnienia
- umowy o służebności
Powykonawcza dokumentacja techniczna
Co zyskujesz z iDokiem?
5-10 razy szybsze wprowadzenie informacji z dokumentów do bazy danych
dzięki automatyzacji
Szybszy dostęp do aktualnych i szczegółowych informacji z dokumentacji
łatwe wyszukiwanie po atrybutach
Bardziej kompletne bazy danych
większa łatwość wprowadzania danych to więcej scyfryzowanych dokumentów.
Dane lepszej jakości
pozbawione błędów wynikających z pracy ludzkiej
Przyspieszenie procesów w firmie
dzięki łatwiejszemu i szybszemu dostępowi do aktualnych danych pozyskanych z dokumentów
Większa kontrola nad procesami
szybki wgląd w dokumentację pomaga lepiej kontrolować ważne terminy, wydane decyzje, itp.
Lepsze wykorzystanie potencjału pracowników
czas wcześniej przeznaczony na żmudne przepisywanie danych mogą wykorzystać na inne zadania
Niższe koszty rekrutacji i szkolenia
mniejsza rotacja pracowników na stanowisku związanym z wprowadzaniem danych
Lepsze zarządzanie czasem pracy
iDoc może przetwarzać dokumenty również poza zwykłymi godzinami pracy (np. w nocy, bez przerw)
Przekonaj się, jak iDoc ułatwi pracę w Twoim przedsiębiorstwie
Sprawdź, jak dzięki iDocowi zyskasz wygodny i szybki dostęp do pełnej i aktualnej informacji z dokumentacji papierowej. Wykorzystaj w pełni jej potencjał do sprawniejszego zarządzania przedsiębiorstwem i podejmowania lepszych decyzji operacyjnych i strategicznych.

Chcesz widzieć swoją dokumentację na mapie?
Jeśli w przedsiębiorstwie posiadasz dokumentację, która dotyczy obiektów w terenie, dostęp do teczek dokumentów z poziomu mapy może znacznie ułatwić pracę.
Takie możliwości daje LocDoc – rozwiązanie, które podobnie jak iDoc, wykorzystuje AI/ML do automatycznego czytania i kategoryzowania zeskanowanych dokumentów. Na podstawie odczytanej lokalizacji rozmieszcza te dokumenty na mapie tworząc tzw. przestrzenną bazę danych.
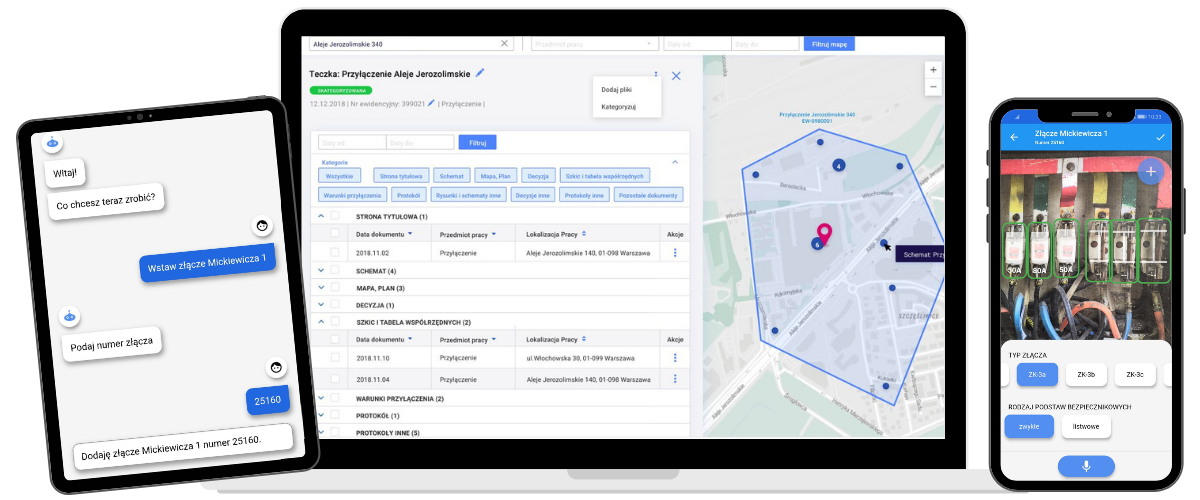
iDoc oraz LocDoc to część platformy GlobIQ do budowania i utrzymania cyfrowego modelu majątku sieciowego.
Najczęściej zadawane pytania:
Jaka jest skuteczność odczytania informacji z dokumentów?
Dla kategoryzacji dokumentów oczekiwana skuteczność wynosi 80+%. W praktyce obserwujemy skuteczność powyżej 95% dla danej kategorii.
Dla odczytania wszystkich atrybutów z dokumentów dla danej kategorii oczekiwana skuteczność wynosi 80+%. W praktyce obserwujemy skuteczność powyżej 85%
Czy iDoc odczytuje pismo odręczne?
Rozpoczęliśmy prace nad odczytywaniem pisma odręcznego przez iDoka. Na dziś dzień system potrafi odczytać pismo ręczne pisane w postaci drukowanej i osiąga najwyższą skuteczność w przypadku cyfr. Pracujemy nad zastosowaniem kolejnych algorytmów, które pozwolą iDokowi odczytywać także bardziej naturalne pismo ręczne.
Czy system poradzi sobie z odczytaniem każdego typu dokumentu?
Modele można wyuczyć do rozpoznawania prawie każdego typu dokumentu. Natomiast każdy nowy typ dokumentu, o nowej strukturze informacyjnej wymaga analizy i nauczenia nowego modelu AI do rozpoznawania zdefiniowanych/oczekiwanych informacji. Poziom trudności w rozpoznaniu różnych dokumentów i informacji jest różny. Jedne są bardzo proste do interpretacji a inne bardzo trudne, dlatego też zasadą jest, że im więcej danych dostępnych do nauki, tym bardziej prawdopodobne, że iDok będzie rozpoznawał atrybuty dokumentów z najwyższą skutecznością.
Może się też zdarzyć, że dwa typy dokumentów będą na tyle do siebie podobne, że ich rozróżnienie przez automat będzie mniej skuteczne niż byśmy tego oczekiwali.
Ile trwa nauczenie odczytywania danych z nowego rodzaju dokumentu?
Przygotowanie jednego modelu zajmuje minimum tydzień trwa –jeśli mamy dostępne odpowiednie dane. Jeśli przykładowo z jednego dokumentu są do odczytania 3 atrybuty. To potrzebujemy 4 modeli: jeden do rozpoznania kategorii tego dokumentu i 3 do rozpoznania każdego z atrybutów. Czas przygotowania to więc w tym przypadku ok. 1 miesiąca.
Czy przechowujecie dane? Jeśli tak, to jakie i w jakim celu?
Aby móc monitorować błędy popełniane przez model oraz aby móc dany model w przyszłości douczyć, zbieramy potrzebne do tego dane.
Dane przeznaczone do uczenia są zapisane w pliku i przechowane w bezpiecznej lokalizacji (usłudze Google Cloud Storage). Dane te zawierają m.in.:
pełen tekst dokumentu,
zatwierdzoną kategorię dokumentu
znalezionych kandydatów dla atrybutów,
wyłonionych kandydatów,
zatwierdzone wartości atrybutów wraz z ich powiązaniem do miejsc (położenie na stronie) w dokumencie.
Jak zapewniacie bezpieczeństwo odczytanych danych?
Dane uczące są przechowywane w odrębnym wolumenie („bucket”) w usłudze przeznaczonej do przechowywania plików, Google Cloud Storage. Wolumen ten jest szyfrowany z użyciem kluczy, udostępnionych przez dostawcę usług chmurowych. Aplikacja ma dostęp do tego wolumenu poprzez autoryzowane konto systemowe. Dostęp do tego wolumenu mają również pracownicy Globemy oraz użytkownicy po stronie klienta, ale tylko z użyciem imiennych kont. Operacje dokonywane na tym wolumenie są rejestrowane (tzw. audit logs) z użyciem standardowych mechanizmów Google Cloud.
Ponadto skopiowane dane są trzymane na naszym wewnętrznym szyfrowanym serwerze, który przeszedł audyt bezpieczeństwa przeprowadzony przez zewnętrzną firmę. Po douczeniu modelu dane są usuwane.
Ponadto dane są zabezpieczane w następujący sposób:
Zabezpieczanie transmisji
Eliminujemy możliwość niepowołanego dostępu do usług poprzez filtrowanie adresów IP żądań przychodzących do serwera (firewall). Dostęp można uzyskać tylko z określonej puli adresów, która jest edytowana przez admina.
Transmisja pomiędzy poszczególnymi maszynami (komputerami, serwerami) jest zabezpieczona z użyciem protokołu TLS w wersji 1.3.
Uwierzytelnienie i autoryzacja
System iDoc wykorzystuje mechanizm KeyCloak i umożliwia uwierzytelnianie i autoryzację użytkowników poprzez:
użycie OpenID Connect (OAuth2) lub SAML 2.0
integrację z LDAP lub Active Directory
konta lokalne
KeyCloak jest zainstalowany wraz z innymi komponentami na wydzielonej infrastrukturze i obsługuje tylko system iDoc.
Uwierzytelnienie wywołań integracyjnych systemu zewnętrznego w usłudze odbywa się z użyciem identyfikatora klienta i klucza prywatnego.
Jak długo trwa wdrożenie systemu, który będzie gotowy do wykorzystania?
Produkt z półki można wdrożyć po zbudowaniu architektury, co może zająć około miesiąc, jednak, aby rozwiązanie mogło odczytywać dane, których oczekuje klient, musimy nauczyć i odpowiednio dostosować modele. Długość tego procesu jest uzależniona od ilości danych, jaka jest do odczytania. Przewidujemy około tygodnia na nauczenie jednego modelu. Jeden model pozwala aplikacji odczytać jeden atrybut lub jedną kategorię dokumentu. Jeśli więc mamy do odczytania przykładowo jeden rodzaj ( kategorię) dokumentu, zawierającą trzy atrybuty (trzy pozycje w dokumencie), będziemy potrzebowali dostosować 4 modele.
Jaka jest cena rozwiązania i co się w niej zawiera?
Cena zależy od przyjętego modelu sprzedażowego oraz miejsca utrzymywania architektury:
On-Premises czy
SaaS
W rozwiązaniu SaaS
Składniki ceny (na miesiąc):
Utrzymanie infrastruktury, administrowanie oraz wsparcie techniczne:
Zależne od:
liczby licencji,
poziomu SLA,
infrastruktury
Opłata zmienna za przetwarzanie dokumentów (OCR, kategoryzacja, odczyt atrybutów):
Zależna od:
liczby stron,
ilości informacji
Pakiet liczby stron do wykorzystania.
Określona liczba str. / rok
Rabat % za wykupienie pakietu na 1 lub 2 lata
Składowe ceny usługi – wykonania projektu
| Analiza danych i zaprojektowanie modeli | Cena zależne od:
|
| Dostosowanie iDoka, przygotowanie danych do uczenia, przygotowanie modeli, dokumentacja projektowa i użytkowa, testy, wdrożenie, szkolenie, konsultacje. | Cena zależne od:
|
| Przetworzenie archiwalnych dokumentów | Cena zależne od:
|
| Integracje z systemami firmy | Cena zależna od wyniku analizy technicznej |
| Dodatkowe funkcje – Customizacja | Cena zależne od wymagań i analizy funkcjonalnej |