FME ma wiele funkcjonalności, a jedną z nich jest możliwość podłączania się do bazy i wykonywania na niej różnych operacji. Sprawdź, jakie oferuje możliwości w zakresie hurtowych aktualizacji baz danych.
Tworzenie połączenia FME – Baza
Przed czytaniem z bazy lub zapisywaniem do niej, należy stworzyć autoryzowane połączenie. W FME Workbench można to zrobić wchodząc do Tools > FME Options > Database Connections. Wtedy wyświetli się okno z listą dostępnych połączeń:
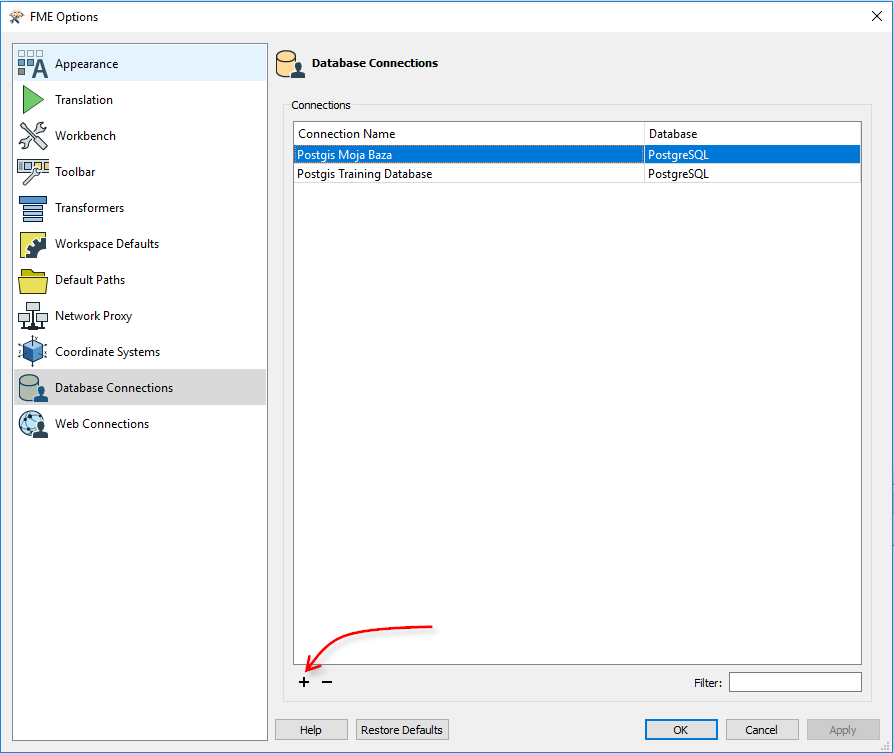
Żeby stworzyć nowe połączenie, klikamy w przycisk z plusem i otwiera się okno konfiguracji:
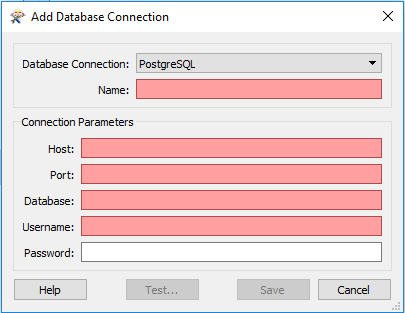
Należy wpisać dane bazy, przetestować i zaakceptować. Raz zdefiniowanego połączenia możemy używać kiedy chcemy. Będzie też dostępne w Przeglądarce. Teraz wczytajmy dane do bazy.
Zapisywanie danych do Bazy
Nie mamy jeszcze żadnych rekordów w bazie, więc zacznijmy od zapisania do niej danych. Wejdźmy do FME Workbench i wygenerujmy skrypt. Otworzy się okno do zdefiniowania transformacji:
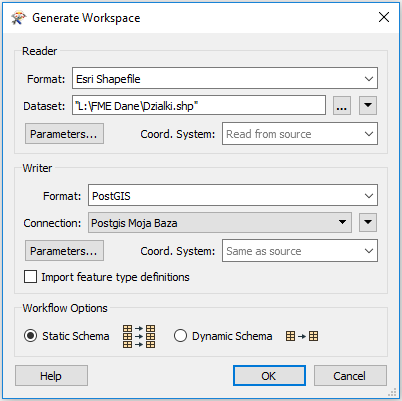
Dane z działkami ewidencyjnymi z Krakowa, które posiadamy w postaci pliku SHP wczytajmy do bazy PostGIS (baza PostgreSQL z przestrzennym rozszerzeniem). Dzięki temu, że wcześniej zdefiniowaliśmy połączenie do bazy, nie musimy teraz wypełniać jej parametrów. Akceptujemy i wynikiem jest następujący skrypt:

Po lewej stronie znajduje się reprezentacja warstwy SHP z atrybutami obiektów, które się na niej znajdują. Po prawej jest zobrazowanie tabeli w bazie danych.
Konfiguracja Bazy Danych
Podczas pracy z bazą danych, najważniejsze ustawienia każdej tabeli znajdziemy klikając w ustawienia reprezentującego ją obiektu (ikonka koła zębatego).
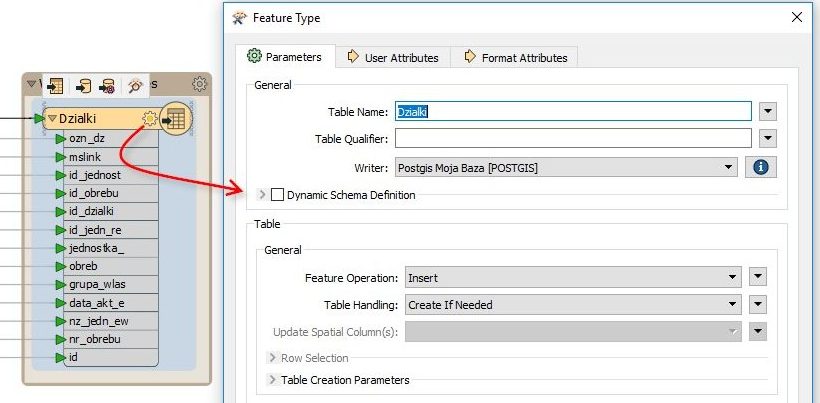
W oknie tym można między innymi zmienić nazwę tabeli, lub wybrać do jakiego schematu bazy chcemy wpisać dane (Table Qualifier).
Najważniejszy parametr (Feature Information) mówi nam o tym jaką operację wykonujemy na bazie – w tym wypadku, że wczytujemy dane do bazy. Można też wybrać sposób, jak program będzie się obchodził z tabelą (Table Handling).
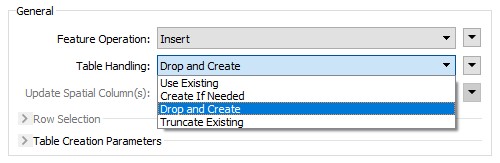
Można wybrać, aby program tworzył tabelę niezależnie od jej istnienia (Drop and Create), stworzył ją, jeśli jeszcze nie istnieje (Create if Needed), dodał do istniejącej tabeli (Use Existing), lub opróżnił, jeśli istnieje (Truncate Existing).
Opcje jak obchodzić się z tabelami (Table Handling) wybieramy zależnie od efektu, który chcemy uzyskać. W tym momencie wybierzmy Create if Needed. Przewaga nad Drop and Create polega na tym, że jeśli inny użytkownik ma już taką tabelę, to nie usuniemy mu zawartości.
Włączmy skrypt i spójrzmy na dane wyjściowe w Przeglądarce:
 Czasami może się okazać, że w danych wejściowych powstała jakaś zmiana i należy zaktualizować bazę danych na podstawie nowego zestawu danych.
Czasami może się okazać, że w danych wejściowych powstała jakaś zmiana i należy zaktualizować bazę danych na podstawie nowego zestawu danych.
Aktualizacja rekordów Bazy Danych
Powiedzmy, że otrzymaliśmy nowy zestaw danych Dzialki_update. Najprostszy sposób to wykonać taki sam proces jak wcześniej, tylko ustawić Drop and Create. Tym sposobem zamienimy stary zestaw danych na nowy:
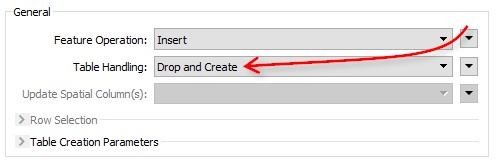
Takie rozwiązanie opiera się na założeniu, że Dzialki_update to cały zestaw danych. Co jeśli zawiera tylko rekordy, które wymagają aktualizacji? Dla bezpieczeństwa zmieńmy rodzaj operacji z wstawiania (Insert) na aktualizację (Update), a jako sposób obchodzenia się z tabelami wybierzmy używanie istniejącej (Use Existing).
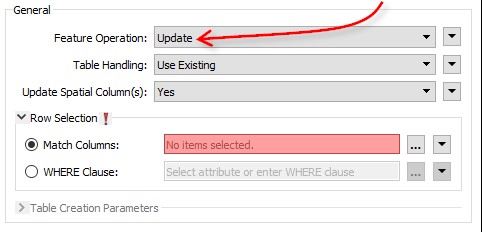
Kiedy wybraliśmy aktualizację pojawił się nowy parametr – dopasowanie kolumn (Match Columns). Użyjemy go do zdefiniowania połączenia między starymi i nowymi danymi. W tym przypadku mamy atrybut ID_DZIALKI w danych wejściowych i kolumnę id_dzialki w bazie danych, więc użyjmy tego atrybutu:
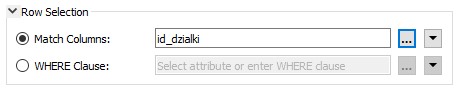
Działa to tak, że jeśli przychodzący obiekt ma wartość atrybutu ID_DZIALKI=12, to jego parametry zostaną użyte do zaktualizowania rekordu bazy danych, w którym id_dzialki=12.
Takie rozwiązanie jest wystarczające, ale możemy zamiast tego użyć warunku gdzie (where). To pozwala zdefiniować łączenie samemu, oraz dodać warunek:

W tym przykładzie zaktualizujmy tylko działki z obrębu czternastego. Poza tym obrębem dane nie zostaną zaktualizowane nawet jeśli identyfikator działki będzie się zgadzał.
Wiemy już jak wykonać aktualizację, a co jeśli chcemy z bazy usunąć jakieś dane?
Usuwanie rekordów z bazy danych
Załóżmy, że Dzialki_deletions to zestaw danych z działkami, które mają zostać usunięte z bazy danych. Żeby to zrobić zmieńmy rodzaj operacji z aktualizacji (update) na usunięcie (delete). Warunek dopasowania zostawmy taki sam. Rekordy z bazy danych, które będą miały pasujący identyfikator i obręb zostaną usunięte.
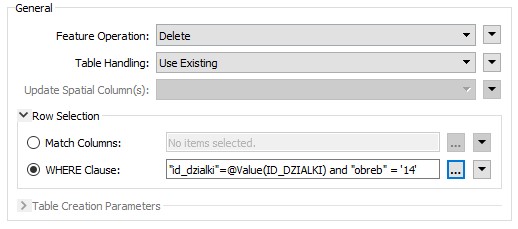
Jak widać usuwanie nie jest trudniejsze od aktualizowania, co jeśli chcielibyśmy usuwać i aktualizować w tym samym momencie?
Usuwanie i aktualizacja rekordów bazy danych
Załóżmy, że część przychodzących danych to aktualizacje, a część jest do usunięcia.
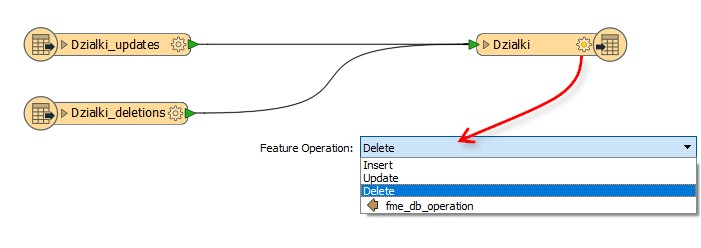
Oczywiście nie ustawimy usuwania i aktualizacji w jednym momencie. Zamiast tego oznaczmy każdy obiekt operacją, którą na nim chcemy wykonać. Użyjemy do tego atrybutu fme_db_operation i funkcji AttributeCreator:
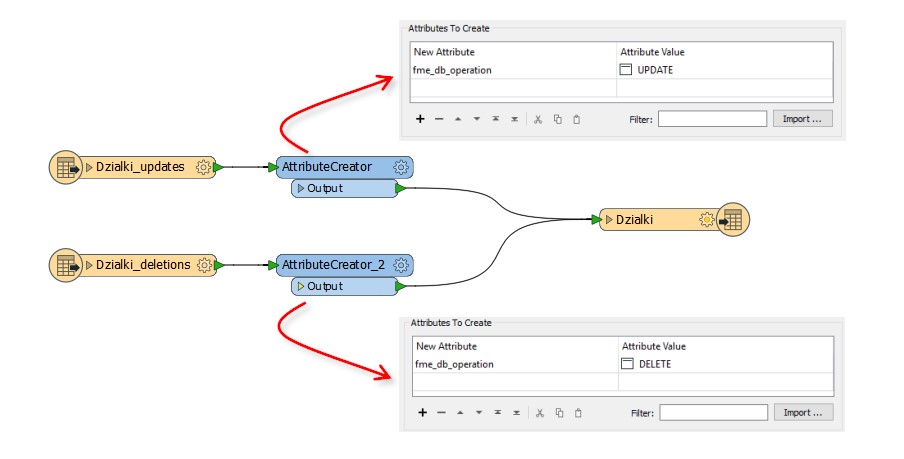
Dzięki temu do każdego źródła danych dodamy atrybut mówiący o rodzaju operacji i nadamy mu pożądaną wartość. Właśnie tak oznaczyliśmy, które dane będą aktualizować rekordy, a które je usuwać.
Należy pamiętać o wskazaniu typu operacji w ustawieniach wyjścia danych.
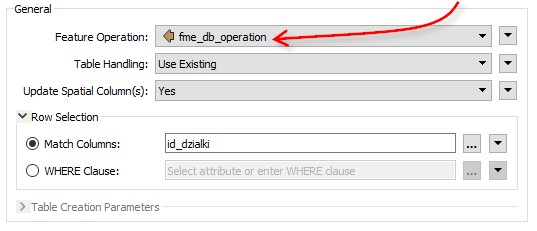
Teraz kiedy uruchomimy skrypt obiekty z wartością UPDATE zaktualizują rekordy w bazie. Obiekty oznaczone DELETE wskażą co ma zostać usunięte. To wszystko oczywiście opiera się na połączeniu po identyfikatorach działek.
To rozwiązanie zakłada, że wiemy które dane są do usunięcia, a które do aktualizacji. Dane dostaliśmy już podzielone na dwa zestawy danych. Gdybyśmy nie byli pewni zawsze możemy najpierw wykryć zmiany w zbiorze.
Wykrywanie i aktualizowanie zmian
Zmiany będziemy wykrywać porównując nowy zestaw danych z istniejącymi już rekordami:
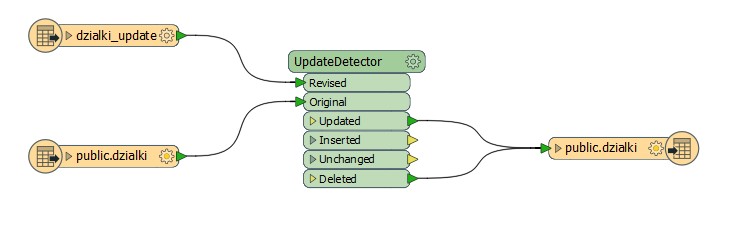
Dodajmy dwa wejścia danych – jedno czyta obecną zawartość bazy danych (public.dzialki), drugie to plik działki_update.shp, z którym funkcja UpdateDetector porówna rekordy bazy danych, wykryje zmiany i odpowiednio zaktualizuje. Zmiany można wykrywać na podstawie atrybutów, relacji przestrzennych, lub obu tych warunków.
Teraz zapis do bazy danych – tym razem nie musimy tworzyć atrybutu fme_db_operation, ponieważ funkcja Update Detector robi to za nas. Trzeba natomiast sprawdzić w ustawieniach bazy czy ustawiona jest dobra operacja, oraz odpowiednia kolumna do dopasowania danych.
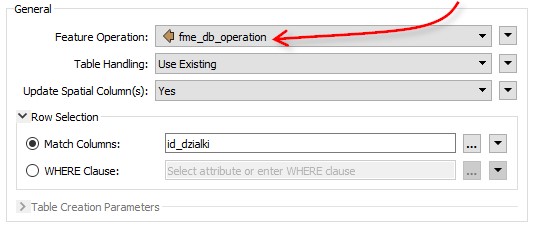
A co jeśli każdy obiekt powinien zostać zaktualizowany na podstawie innego warunku? Wtedy połączenie można wpisać do atrybutu i użyć go przy ustalaniu warunku gdzie (where). Wtedy każdy obiekt ma swój odrębny warunek.

Podsumowanie
W tym przykładzie użyliśmy bazy PostgreSQL, ale większość baz danych ma w FME identyczny interfejs, więc praca na innym formacie bazy danych nie powinna być problemem. Mamy nadzieję, że przygotowane przez nas praktyczne przykłady były interesujące i tematyka aktualizowania baz danych stała Ci się bliższa. Powodzenia w dalszej pracy!